Live migrating a Kubernetes cluster across VPCs without downtime
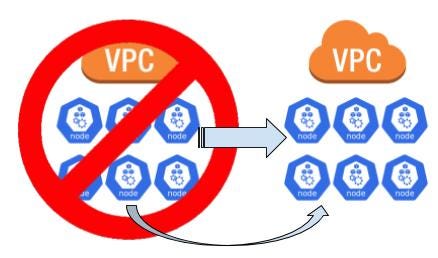
Recently I ran into a situation where we had an IP conflict with another team’s Kubernetes cluster where they had a pod network CIDR block that conflicted with the CIDR block of the VPC my cluster (as well as legacy EC2 instances) was in. My team’s cluster could talk to their cluster over VPC peering but they couldn’t talk to me the same way. We didn’t want to put any of the application ingresses on the public internet and for internal limitations we couldn’t extended my VPC’s CIDR block. The only solution that could be found was to setup a VPC with a different CIDR block. This is easy enough to handle for the EC2 instances outside the Kubernetes cluster but live migrating a cluster without downtime was a bit of a challenge. Due to the application deployment pipeline the clusters have become pets to the engineering teams. That introduces a set of problems where spinning up & migrating to a different cluster isn’t possible without a significant time investment across many teams. Doing this migration without downtime seemed daunting but as the scope was defined if started to become a reasonable goal.
NOTE: At the last minute it was decided to not do this migration. The steps I describe below were executed several times in the lab environment without issue but it never went to the production migration stage. :(
Not all work ends up in production and this turned out to be one of those times. However, I still think the process is worth sharing. :)
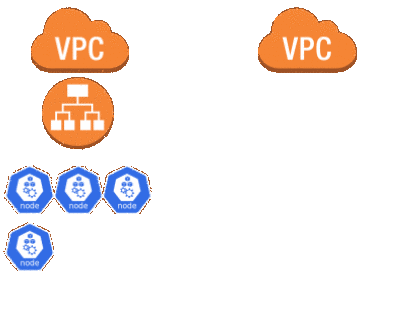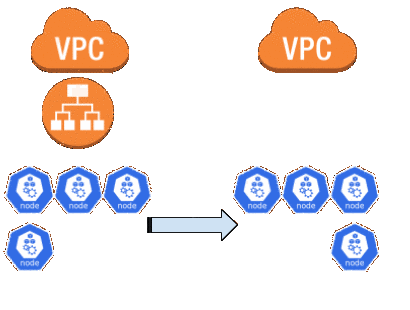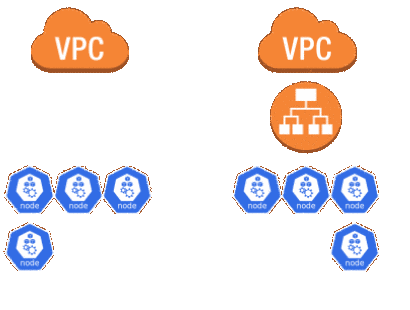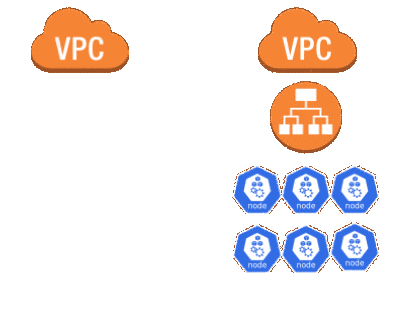
What the cluster looked like
I’m a big fan of the Hashicorp’s Infrastructure As Code toolset and they work well for my environment. For cluster deployments I build an AMI using Packer, deploy it to the AWS AutoScalingGroup(s) with Terraform, and then run a custom Python script to cycle the nodes. The Terraform code has 3 main components; a module (worker-common) for shared resources (security groups, LBs, DNS, etc), a module (control-plane) for the control-plane, and a module (worker-{pool}) for the worker nodes. There are around 72 AutoScalingGroups (one per instance-type per AZ plus on-demand vs spot), about 200 worker nodes, and many thousands of Pods running on the cluster I needed to migrate.
The Terraform code essentially looked like this:
The problems
With Terraform the configuration is declarative and because of assumptions made in the code I had a few problems to solve.
- Can’t duplicate names for InstanceProfiles, AutoScalingGroups, and LoadBalancers
- Can’t register instances to a TargetGroup that is in a different VPC
- SecurityGroups can’t be used across VPCs; though they can be referenced in rules
- The DNS entries were CNAMEs to the LBs not A records
Walking through the solution steps
I broke the problem into pieces and tackled each one individually. The basic order of operations was something like this. I’ll be walking through each piece below.
- Create the new VPC
- Setup the shared resources in both VPCs
- Create additional worker nodes in the new VPCs
- Route traffic to both VPCs
- Route traffic to just the new VPC
- Migrate the workloads to the nodes in the new VPC
- Migrate the control-plane nodes to the new VPC
- Clean up the old resources
Again, this seems like a lot to do but it turned out to not be as much as I had originally thought it would be. One of the things that made it easier was a rich set of tags on all our AWS resources. I was able to clearly reference them in the Terraform code and do data resources accordingly.
Creating the new VPC
First thing was creating the new VPC. This was pretty straight forward except for coming up with a name that everyone was happy with. Both VPCs were peered with each other so that everything could talk privately to each other.
Setting up shared resources
Once that was created, I started to tackle the resource naming pattern and that too turned out to be pretty easy to solve. I added a new parameter to the worker-common Terraform module that allowed me to set a suffix to each resource. By default the variable was empty so no prefix was added and the existing resources were not impacted. I could then setup a worker-common-migration module that creates the new resources in the new VPC. Because I didn’t need to move the InstanceProfile (it’s not VPC specific) I added a flag for whether or not the code should create it.
I put in a bit of a hack for the SecurityGroups so that during the migration the “shared” SecurityGroup references both the old & the new IDs. This is possible because the new VPC is peered to the old VPC.
Now I could run Terraform so the LBs & SecurityGroups would be created in the new VPC. Once the Terraform run is completed the new “common” resources exist but nothing is using them yet.
The worker nodes
Next up was creating worker nodes in the new VPC. Unlike with worker-common, I didn’t need to create a migration module for the workers. I just needed to add a new one (x24!) that referenced the newly created resources.
Before I could run terraform apply though I needed to update the Ingress controller. I had to change the Service to externalTrafficPolicy: Cluster so when the ingress controller started running on the nodes in the new VPC the traffic would still be routed to them. Remember, I can’t add the new workers into the same TargetGroup as the existing ones because they are in a different VPC. This created an increase in latency for every request through the ingress controller because the NodePort had to be proxied but it was low enough, and for such a short period of time, that it was considered acceptable. After the new workers were created, I added a taint to the old AutoScalingGroups so that no new Pods would be scheduled onto them.
for node in $(aws ec2 describe-instances --filters "Name=tag:KubernetesCluster,Values=CLUSTER_NAME" "Name=vpc-id,Values=OLD_VPC_ID" | jq -r '.Reservations[].Instances[].PrivateDnsName')l do
kubectl taint nodes $node migration=migration:NoSchedule
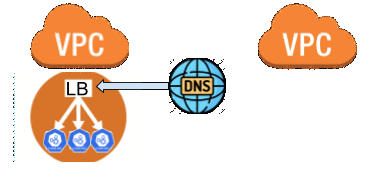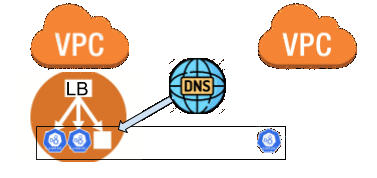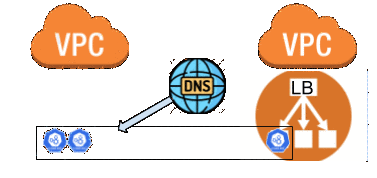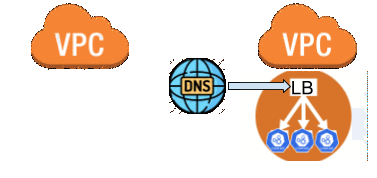
doneNow that I had new workers in the new VPC and they were all able to talk to each other in both VPCs, I was ready to cutover DNS and point it to the new LBs. So far, the total migration time has been only ~20 minutes and I’m meeting my goal of zero downtime.
Migrating the workloads
At this stage, I need to start shifting the workloads from workers in the old VPC to the workers in the new VPC. I manually evicted the Ingress controller pods which moved them onto workers in the new VPC. This allowed me to switch back to externalTrafficPolicy: Local and get the ingress latency back to normal. A couple minutes later this was done and I could start moving the live workloads. Luckily for me, our Python deployment script allows for cycling nodes based on a label filter. I kicked off the job and it started draining the old worker nodes. As each node was drained the workloads automatically shifted only onto the new worker nodes thanks to the taint I had added. Moving workloads while respecting the PodDisruptionBudgets can be slow and for the live cluster it was expected to take about 4 hours. Working with the lab cluster had this step done in ~30 minutes.
Code cleanup
While I still had the control-plane to migrate I wanted to clean up the Terraform code to start removing the dueling modules. I flipped the worker-common-migration module to use create_instance_profile = "true" and did the opposite in the original worker-common module. I then moved the resources in the Terraform state from one module to the other.
terraform state mv module.worker-common.aws_iam_instance_profile.this module.worker-common-migration.aws_iam_instance_profile.thisterraform state mv module.worker-common.aws_iam_role.readonly module.worker-common-migration.aws_iam_role.readonlyterraform state mv module.worker-common.aws_iam_role.this module.worker-common-migration.aws_iam_role.thisterraform state mv module.worker-common.aws_iam_role_policy.this module.worker-common-migration.aws_iam_role_policy.this# etc, etc
I pointed all the worker modules to the new migration module’s output using sed.
find . -type f -name "*.tf" -not -path '*/\.terraform' -exec gsed -i 's/module.worker-common.instance_profile_id/module.worker-common-migration.instance_profile_id/g' {} +I removed the original worker-common.tf and changed the module source that the worker-common-migration.tf was pointing to.
module "worker-common-migration" {
source = "../modules/worker-common"
# the rest of the code is the same
}Even though the module was now called worker-common-migration the code it is using is now the same as all of the other clusters. The parameters still point to the new VPC but the code used is the same and that’s the important part for future development & maintenance. The next Terraform run removed the old AutoScalingGroups and SecurityGroups as they were no longer needed. Now, all that is left is to do the control-plane.
The control-plane
With the control-plane things start to get tricky. I can’t have more than one node using the same etcd volume and writing to it at the same time. This means that I am going to have to stop one of the nodes, recreate it in the new VPC and then bring it live with the other nodes still running. I can only do one at a time if I don’t want to lose quorum on etcd. Because of the way the control-plane security groups were created inside of the same module that creates the control-plane nodes I wasn’t able to do the same sort of trick as I did with the workers. Instead, I used a variable called extra_security_groups that could be used to attach an extra SecurityGroup to the control-plane nodes. I broke a rule and manually created a SecurityGroup in the existing VPC that had the same rules and manually attached it to each control-plane node. This meant it was now safe for Terraform to delete the original SecurityGroup and recreate it in the new VPC.
The code calling the module was then updated to point to the new VPC and subnets (e.g., data.aws_subnet.private-migration.*.id). Instead of running a general terraform apply I needed to run each migration step using Terraform’s -target flag for the resources that I wanted to migrate first.
terraform apply -target module.control-plane.aws_security_group.control-plane -target module.control-plane.aws_security_group_rule.control-plane-egress -target ... -target ... # etc etcHowever, I ran into the problem of the LB that runs in front of the control-plane nodes. I needed to be able to balance across 2 different VPCs and that isn’t possible with a TargetGroup. Managing the DNS entries and changing them at precisely the right time during the migration was difficult with our code setup so I decided to break another rule and manually updated the DNS entry. I changed it from pointing to the LB and to be the A records of the first control-plane node in the new VPC. This enabled me to keep full uptime on the api calls made from outside the cluster.
I removed the extra_security_groups parameter and ran another targeted apply to recreate just a single set of control-plane resources.
terraform apply -target module.control-plane.aws_autoscaling_group.this.2 -target module.control-plane.aws_autoscaling_group.etcd.2 -target module.control-plane.aws_launch_template.this.2 -target module.control-plane.data.template_file.user_data.2 # etc etcThis left me with one part of the control-plane in the new VPC and the rest in the old. Now that I had part of the control-plane running in the new VPC I could safely have Terraform, through another -target apply command, recreate the LB in the new VPC. It would have just the single apiserver node in it but that’s okay because external calls to the Kubernetes API are pretty low and it could handle the load. The internal calls use the kubernetes.default Service and are unaffected by these changes. Once the LB was been recreated, I was able to switch the DNS back to the configuration that is a CNAME to the LB.
I ran the terraform apply -target ... -target ... again for the next piece of the control-plane and that was moved as well. Rinse & repeat one more time and the control-plane was running in the new VPC!
The migration of the control-plane was a lot more manual than I prefer but it got the job done in about 30 minutes. The majority of that time was waiting on the AWS resources to be created and to come online. In general, because of the way we build our AMIs, it takes 4–7 minutes from when a node starts to boot and become ready in the Kubernetes cluster.
More cleanup
At this stage the the cluster is fully migrated but the code was messy. I made another pass through the code and got rid of all the data.aws_subnet.private-migration code. It was updated to use the new VPC only in the lookups and the references were pointed back to the original data.aws_subnet.private. The worker-common-migration name for the module in the app will always be there. Well… unless it starts to bug me too much and I do all the terraform state mv commands to move it but that seems like a lot of risk for no real value.
However, all the AutoScalingGroup still have names with the -migration suffix and that could be considered confusing if someone was looking at the AWS resources. I setup another set of workers without the asg_suffix and set a taint on the ones with -migration the same way I did for during the migration. All new workloads will now go onto these new ASGs and slowly drain off the old over time or whenever the next deployment is released; there’s no benefit to cycling the cluster again now. Once all the workloads are off the -migration tier I’ll remove that code from Terraform as well.
Final thoughts
In short, this was a huge pain to go through but I’m kind of glad that I had to do it. I’m disappointed that it never went all the way through to production but that’s the way things work sometimes. I think I learned more about the way the code worked than I did writing it in the first place. Sounds strange to say that but it’s true. When I wrote most of the original code I had to think about how things related to each other but in the 2 years since then I’ve never really had to think about it.
In the future, I’m looking forward to when IPv6 is inside our VPCs and data centers. Assuming you don’t do something … unique … that’ll make IP conflicts a thing of the past. I’m not sure when we’ll end up doing this but thankfully Kubernetes has made this possible when the time comes.

