Kubernetes Cluster Autoscaler — In for a penny, in to infinity
I had an interesting conversation with a coworker in another business unit the other week where we were talking about instance types and planning for unknown workload sizes in our Kubernetes clusters. They asked what memory-to-cpu ratios my team used to decide the instance types to run for our clusters. I had to call timeout and talk about why ratios didn’t matter because I was using the cluster-autoscaler. I realized we needed to take a step back and go over the philosophy I use when running workloads on Kubernetes. I figured it might make an interesting blog post so here we are.
Like a lot of people, the Kubernetes clusters I manage look like they were setup by kubeadm for the control-plane with multiple apiservers, etcd, etc. Maybe you run etcd on a separate tier of VMs, maybe you don’t, but in the grand scheme of things we’re all doing things pretty much the same way. Where it starts to get interesting is with the worker nodes. Some people run one instance type, others run multiple types. Some people have a fixed size of the cluster and others run the cluster-autoscaler. As you probably got from the title, I’m one of those who use the cluster-autoscaler and rely on it heavily for my workloads.
From an overly simplistic perspective, as a cluster operator I don’t really care what someone requests for memory & cpu for their applications. I care a great deal from a SRE and/or business perspective but let’s ignore those hats for the moment.
What matters is that the Scheduler can schedule the requested workload.
What matters to me is that the cluster has the resources to run the workloads that rely on it. Obviously we can’t run thousands of nodes just in case something needs it one day; that’s where the cluster-autoscaler comes in. The cluster-autoscaler watches for when Pods fail to schedule due to unavailable resources and scales the cluster nodes so that those resources become available. It can also reschedule workloads from under-utilized nodes so that the cluster scales down to a smaller size. On AWS it can do this scaling via node templates or AWS AutoScalingGroups and in my environments we heavily rely on AutoScalingGroups.
Much like my colleague, when I first created Kubernetes clusters I thought the ratio for cpu & memory was important. We were not sure what the workloads requirements were going to be like so we went with the generic m5d.8xlarge instance type. This of course worked and the cluster ran fine. The problem was that we were having trouble getting the cluster utilization numbers above 10-15%. The binpacking wasn’t fitting the Pods in a way that used most of the resources for a node. I ended up spending a bunch of time working with teams to make sure they were setting appropriate resources requests/limits and educating people about how to figure that out on their own. The education portion was time well spent but overall the effort barely moved the needle. We got up to ~23% memory & 7% cpu utilization which means all that work barely made an impact.
After about a year of running this way we wanted to start running the majority of the development cluster on spot instances. The cluster costs were rising and it needed attention before it spiraled out of control. Enabling a pool of spot nodes wasn’t hard as the code already had the concept of multiple worker tiers. I had to add some information about spot pricing but otherwise it was good to go.
But a few days later alerts started firing that the cluster was not scaling due to a lack of spot capacity. The cluster-autoscaler was doing its job and trying to scale; there just wasn’t spot capacity of the instance type we were running. The quick & dirty solution was to add another pool of spot instances of a different size. This worked for a day or two before the alerts started again.
Should I create another node pool to fix it?
This is when I started to realize I was looking at the design of the node tiers wrong. I didn’t care if the workload ran on a c5d.4xlarge, m5d.4xlarge, or r5d.16xlarge. I just wanted it to run! So I copy/pasted some Terraform code around and I had 12 worker tiers; one for each instance type running spot. I tested this out in dev and the spot capacity problem went away.
It wasn’t long until it was noticed that the dev cluster’s memory utilization was up to 43% for memory. After discussing it in chat for a bit with my team the light bulb went off. The cluster-autoscaler was picking different instance types based on the size of the workload that needed to be scheduled. The least-waste config option was doing the work by picking what instance type would utilize most of its resources. Sometimes it went on a m5d.4xlarge and sometimes a c5d.4xlarge based on the blended score of CPU & memory.
Why isn’t this being done in production?
I don’t remember who first asked the question about the production cluster’s utilization but it was quickly decided that the same approach, except using non-spot, should be done in production too. Less than 24 hours and 36 AutoScalingGroups later (12 instance types * 3 AZs) the production clusters were running the same sort of configuration. We didn’t force workloads to reschedule immediately so it took a bit of time for the impact to be seen. The charts eventually started showing over 57% memory utilization and ~25% cpu utilization. It wasn’t perfect but it was 2–3x improvement over what was there before!
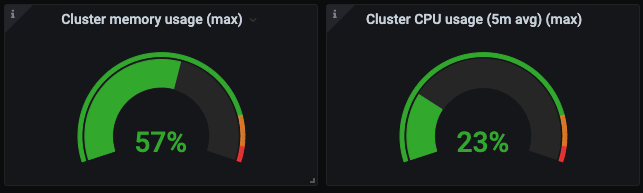
Once spot workloads were added into production there were 72 AutoScalingGroups being managed by the cluster-autoscaler in each cluster. The switch to using so many AutoScalingGroups made a few shifts in thought necessary in order for it to not be overwhelming.
Treat the worker nodes as pieces of compute not cattle.
I found that it can be a different concept to treat something as a piece of compute instead of a herd of cattle. Even if each VM can be replaced, destroyed, or auto-remediated on a whim they have a type and are associated with a grouping. This makes them less ephemeral than something abstract like cpu or memory. Once the thought patterns shifted the code shifted as well. Our deployment script doesn’t need to check that the AutoScalingGroup replaced a node, instead, it can check whether or not the cluster has Pods that can’t be scheduled. No longer does the script need to check whether or not there is existing capacity for rescheduling, it can simply evict the Pods, respecting the PodDisruptionBudget, and trust that the cluster-autoscaler will scale up as necessary. As an added bonus the cluster deployment time went from around 6 hours down to 2–3 hours without noticeable impact on the running workloads.
I can now put back on my other hats and start caring about things like why the cpu usage is so much lower than the cpu requested.
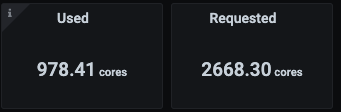
I’m able focus on the things that can impact the bottom line and costs of running these workloads. I can put my attention to application performance and spend my time optimizing the way the apps run on Kubernetes.
Essentially the cluster-autoscaler lets you care about the workloads and not worry about the type of compute it runs on. In the end, isn’t that what really important?

