Initial thoughts on Kubecost
Recently I had the opportunity to install Kubecost on several of the AWS clusters I manage. The tldr is that it was a very helpful and useful system. But to be honest, my initial thoughts were leaning towards the negative until I got it all setup. IMO, like a lot of start-up products, the documentation isn’t the greatest. I felt kind of overwhelmed by what needed to be done and the names of the project vs the docs vs the Github repo didn’t exactly match up (kubecost vs cost-model vs cost-analyzer).
BUT, and this is pretty huge, the Kubecost team was great to work with. They got on a video call, walked us through what I was doing wrong, and helped bridge the gap around what I didn’t understand. And they have a Slack channel to help as well. Once I understood how the components worked together I was good to go. I sent them my feedback about the documentation and hopefully that’ll help the next person who comes along.
As part of my setup, I kept Kubecost isolated from the system Prometheus data so I had to setup a dedicated Prometheus. This meant that even though Kubecost was setup and running, the data wasn’t very useful until there was a day or two worth loaded into the system. I didn’t spend the time to use the exact pricing (RIs, spot, etc); the default pricing model was sufficient for this POC. Once I had the data history the usage patterns instantly became clear. I knew within minutes what namespaces I needed to look at in order to cost-optimize.
At a glance I knew that there was no way that nginx-ingress should account for 15% of a cluster’s costs.
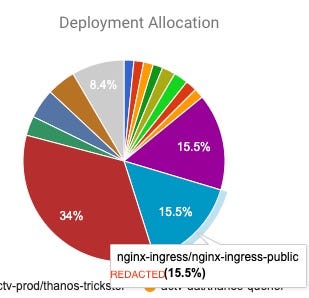
When I looked at the deployment I saw it was requesting 10cpu and 3 pods for an internal cluster that barely gets any traffic. I adjusted the resources requested and the cluster autoscaler quickly reduced the number of workers running. I already had a win and I was just getting started!
Diving deeper into a different cluster I found that a staging namespace was costing more than the production namespace by more than 3x. Another quick click and I saw that the namespace was using 17TB of disk!
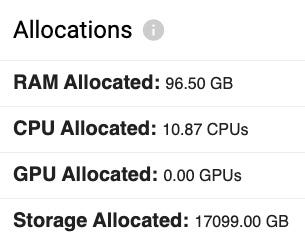
Turns out there was some performance testing done where the number of replicas was increased super high but when the test was stopped the PVCs were overlooked and not cleaned up.
Some of the applications are pretty dialed-in with resource requests & limits while others are not. Thankfully, Kubecost was able to help with this as well.

Using the namespace details dashboard I was able to see Kubecost’s resource recommendations vs what was set in the manifests. In this screenshot I was able to identify that a Thanos sidecar for Prometheus was misconfigured with 30Gi instead of 30Mi of memory. 30Gi of memory for each Prometheus pod across a dozen or more clusters and you’re talking about some real money.
One of the features I like is the ability to allocate “shared” costs proportionally across all applications. We run an ELK (with fluentd) stack for the container logs as a system service that all teams can use. We wouldn’t be running these Kubernetes specific ELK stacks so we consider them part of the cost of doing business on the platform.

With Kubecost I’m able to distribute the costs of the control-plane and ELK, based on their labels, to each of the applications using the Kubernetes platform. I considered allocating the kube-system namespace the same way but I want to know how much these system components & daemonsets were costing us to run.
To set up Kubecost, I used Helm and the cost-analyzer-helm-chart chart from Kubecost. Because I was planning on running this in several clusters (at least 7) I created a wrapper-chart where I could set custom default values for all my deployments as well as a few custom resources for our setup. I kept the default values for the resource requests & limits but that was a mistake. For my larger clusters I was constantly being evicted & OOM’d. If you can, deploy it without limits first to see what’s actually being used and then set the requests/limits accordingly. In the wrapper-chart we also create our Ingress and cert-manager certificates. We create the Ingress in the wrapper so that we can use a shared library chart we have. Lastly we try and set as many of the kubecostProductConfigs variables as possible; though we found some were not able to be set via the Helm chart. One thing to watch out for with this chart is that the Kubecost team modified the values.yaml for the sub-charts distributed with it.
The good:
- Easy to use once setup
- Provides quick insights into where you’re spending $$
- Able to distribute shared costs proportionally across applications
The bad:
- Can be hard to find what you need in the documentation
Verdict:
Install it and try it! If your experience is anything like mine, the cost savings will more than makeup for the price.











